Hash table is a widely used data structure, which serves for effective storing of key-value pairs. Hash table combines benefits of index based search with asymptotic complexity and list traversal with low memory requirements.
Key-value storages
Array
Suppose that we want to store values and later look up for them using some preassigned key. One option might be to use integer as a key and store the element into an array on a position corresponding the the key. Using this approach, the asymptotic complexity of the look up will be evidently constant , because array supports random access. On the other hand, the memory consumption will be immense.
Let's store using this approach opinions of respondents about colors (the color in RGB is used as a key/index). Hence, we will create an array of size . If we ask each of thousand respondents about 5 colors, than we will use at maximum only
of all keys, which means that we have wasted more than
of memory used by the array.
List
We can also use opposite approach – use list to store the values and search sequentially in it. Although it completely eliminates the memory consumption issue (because there are no unused keys), there is a big drawback in the time complexity of the element retrieval, because each search needs steps to be performed.
For example, if we create a (global) survey with millions of respondents, then there will be no efficient way to search the data and find opinions about particular colors.
Binary search tree
Binary search tree can be considered as the golden mean, because in the binary search tree, similarly to the list, do not exist any unused keys and the complexity of the search operation is only . However, we will present even more efficient solution – hash table.
Hash table
Hash table is a data structure, which is built upon an array of fixed length and which uses for addressing a so called hash function. It also guarantees that the search operation will take in average case
operations.
Hash function
The hash function is a function with following properties:
- Consistently returns for the same key the same address.
- It does not guarantee that it will return distinct addresses for distinct keys.
- Uses the whole address space with the same probability.
- The computation of the address is fast.
For example, a very popular implementation of the hash function is based on combination of modular multiplication and addition ( is the key,
is the size of the underlying array):
Collisions
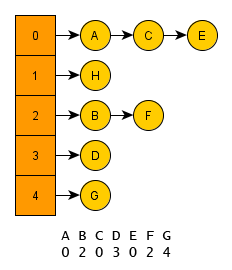
As it was already stated, the hash function does not guarantee assigning of different addresses for different keys. The situation, when the same address is assigned to more objects, is called a collision. There are several ways, how to deal with this situation.
Separate chaining
The most straightforward approach is to store the objects in a linked list (each linked list represents one address). So, when collision occurs, the colliding element is simply appended to the end of the corresponding list. The drawback of this approach is evident – when the table is filled up, the performance of the table degrades linearly with the load factor.
Open addressing
Open addressing (closed hashing) does not use any helper lists to deal with the collisions, it stores the objects on a different address directly in the array. There are two basic procedures how to do it – linear probing and double hashing.
Linear probing
The linear probing strategy at first computes the address of the given element. If the address is empty, then the object is stored there. If the address is occupied, then the procedure iterates over the array, while some address is not empty and the element is stored there.
The schema for saving the element can be formalized using the following function ():
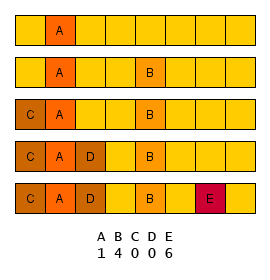
Clustering
Linear probing has a major weakness – clustering. The procedure of storing elements causes creation of clusters of elements, which have very similar address. These clusters have to be traversed linearly when looking up some element. The degradation is even worse then with separate chaining, because each cluster may contain elements represented by several keys.
Removing the elements
When removing an elements, it is necessary to replace the element being removed with the sentinel. A sentinel is a special object, which is considered as an empty space, when a new element is being added (i.e. the sentinel is replaced), and is iterated over, when some element is being looked up.
Alternatively it is possible to resave all remaining elements in the cluster. On the other side, it is not possible to shift the remaining elements one place (address) left, because we could lose access to all other elements with other keys in the cluster (if we remove element shown in the image on the left and shift the rest of the cluster, then we will lose access to the element
).
Double hashing
Double hashing eliminates the creation of clusters by using second hash function instead of the simple iteration. At first, the hashing function computes the initial position and if it is occupied, than the second function is used to compute the shift. If the new position is also occupied, than shift is used again (until the element is saved).
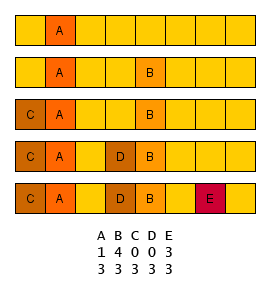
Removing the elements
When removing some element, we must strictly use the sentinel – the double hashing strategy does not form clusters, hence it is not possible to resave the remaining elements.
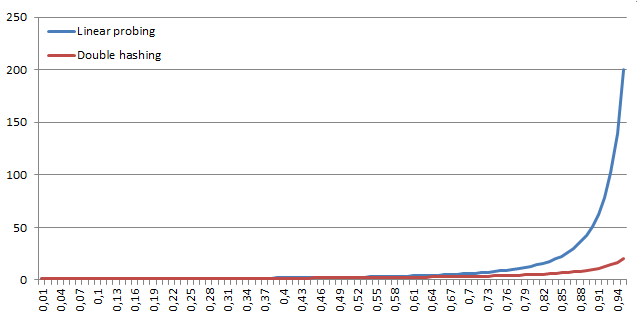
Performance comparison of linear probing and double hashing
For comparing linear probing and double hashing we introduce two metrics – search hit and search miss. Search hit denotes number of operations performed by the algorithm in average case in order to retrieve stored element with given key. Search miss denotes number of operations that must the algorithm perform in order to find out that the element is not stored in the table.
Search hit
Let denote the load factor (
means that the table is
full), then it is possible according to Sedgewick calculate the number of operations performed by linear probing (lp) and double hashing (dh) for search hit as:
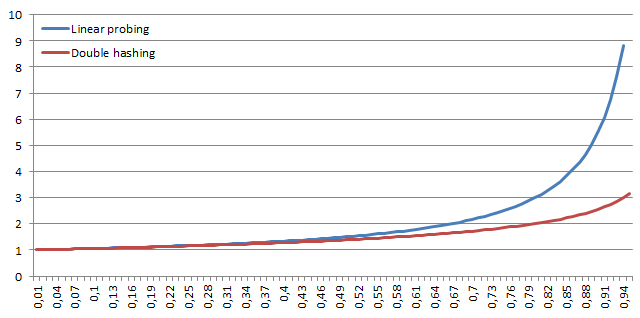
Axis x: α, Axis y: number of operations
Search miss
For search miss similar formula holds:
Axis x: α, Axis y: number of operations
Evaluation of the comparison
From the presented formulas and graphs it stems that the linear probing degrades significantly, when the table is full, while double hashing degrades when the table is
full. We can use these observations, when constructing a hash table with dynamic size of the underlying array as limits of the load. When the limits are reached, we allocate a new table and reinsert all the elements.
Code
/**
* Hash table
* @author Pavel Micka
* @param <KEY> type parameter of the key
* @param <VALUE> type parameter of the value
*/
public class HashTable<KEY, VALUE> {
/**
* Load factor, when reached, new (larger) table is allocated
*/
private final float LOAD_FACTOR = 0.75f;
/**
* Compress factor, when reached, the table is collapsed
*/
private final float COLLAPSE_RATIO = 0.1f;
/**
* Capacity, under which the table will be never collapsed
*/
private final int INITIAL_CAPACITY;
/**
* Number of elements stored
*/
private int size = 0;
private Entry<KEY, VALUE>[] table;
/**
* Constructs hash table with 10 capacity
*/
public HashTable() {
this(10); //vychozi kapacita
}
/**
* Constructs hash table
* @param initialCapacity initial capacity, the table will be never compressed bellow
*/
public HashTable(int initialCapacity) {
if (initialCapacity <= 0) {
throw new IllegalArgumentException("Capacity must be a positive integer");
}
this.INITIAL_CAPACITY = initialCapacity;
this.table = new Entry[initialCapacity];
}
/**
* Inserts the value into the table. If some entry with the same key exists, it will be replaced.
* @param key key
* @param value value
* @return null if value with the given key does not exist in the table, otherwise the replaced value
* @throws IllegalArgumentException if the key is null
*/
public VALUE put(KEY key, VALUE value) {
if (key == null) {
throw new IllegalArgumentException("Key must not be null");
}
VALUE val = performPut(key, value);
if (val == null) {
size++;
resize();
}
return val;
}
/**
* Removes element with the given key
* @param key key
* @return null if element with the given key is not stored in the table, otherwise the removed element
*/
public VALUE remove(KEY key) {
Entry<KEY, VALUE> e = getEntry(key);
if (e == null) { //element does not exist
return null;
}
VALUE val = e.value;
e.key = null; //element is now a sentinel
e.value = null; //remove the reference, so the GC may do its work
size--;
resize();
return val; //return the value removed
}
/**
* Retrieves the value associated with the given key
* @param key key
* @return value, null if the there is no value stored with the given key
*/
public VALUE get(KEY key) {
Entry<KEY, VALUE> e = getEntry(key);
if (e == null) {
return null;
}
return e.value;
}
/**
* Query, if there is a value associated with the given key
* @param key key
* @return true, if there is a value associated with the given key, false otherwise
*/
public boolean contains(KEY key) {
return getEntry(key) != null;
}
/**
* Returns number of stored elements
* @return number of stored elements
*/
public int size() {
return size;
}
/**
* Returns collection of all stored values
* @return collection of all stored values (order is not guaranteed)
*/
public Collection<VALUE> values() {
List<VALUE> values = new ArrayList<VALUE>(size);
for (int i = 0; i < table.length; i++) {
if (table[i] != null && table[i].key != null) {
values.add(table[i].value);
}
}
return values;
}
/**
* Returns collection of all keys
* @return collection of all keys (order is not guaranteed)
*/
public Collection<KEY> keys() {
List<KEY> keys = new ArrayList<KEY>(size);
for (int i = 0; i < table.length; i++) {
if (table[i] != null && table[i].key != null) {
keys.add(table[i].key);
}
}
return keys;
}
/**
* Returns entry corresponding to the given key
* @return the entry
*/
private Entry getEntry(KEY key) {
int index = key.hashCode() % table.length;
//until we reach the empty space
while (table[index] != null) {
if (key.equals(table[index].key)) { //entry exists
return table[index];
}
index = (index + 1) % table.length; //continue with the next address
}
return null; //not found
}
/**
* Performs the put operation itself
*
* If entry with the given key is already present, it will be replaced
*
* @param key key
* @param value value
* @return null if the entry was only added, otherwise value of the replaced entry
*/
private VALUE performPut(KEY key, VALUE value) {
Entry<KEY, VALUE> e = getEntry(key);
if (e != null) {
//entry is in the table
VALUE val = e.value;
e.value = value; //swap their values
return val;
}
int index = key.hashCode() % table.length;
while (table[index] != null && table[index].key != null) { //until we reach an empty space or a sentinel
index = (index + 1) % table.length; //shift to the next address
}
if (table[index] == null) { //empty space
table[index] = new Entry<KEY, VALUE>();
}
table[index].key = key;
table[index].value = value;
return null;
}
/**
* Calculates the expected size of the table
* @return expected size of the table
*/
private int calculateRequiredTableSize() {
if (this.size() / (double) table.length >= LOAD_FACTOR) { //table is overfull
return table.length * 2;
} else if (this.size() / (double) table.length <= COLLAPSE_RATIO) { //table should be collapsed
return Math.max(this.INITIAL_CAPACITY, table.length / 2);
} else {
return table.length; //tabulka has a correct size
}
}
/**
* Changes the size of the table, if necessary
*/
private void resize() {
int requiredTableSize = calculateRequiredTableSize();
if (requiredTableSize != table.length) { //if the table size should be changed
Entry<KEY, VALUE>[] oldTable = table;
table = new Entry[requiredTableSize]; //create new table
for (int i = 0; i < oldTable.length; i++) {
if (oldTable[i] != null && oldTable[i].key != null) {
this.performPut(oldTable[i].key, oldTable[i].value); //reinsert the values
}
}
}
}
/**
* Inner class representing the entries
*/
private class Entry<KEY, VALUE> {
/**
* Key, null == entry is a sentinel
*/
private KEY key;
/**
* Value
*/
private VALUE value;
}
}
Sources
- SEDGEWICK, Robert. Algorithms in Java: Parts 1-4. Third Edition. [s.l.] : [s.n.], July 23, 2002. 768 p. ISBN 0-201-36120-5.